
在自动驾驶城市中用于360度感知环境的语义相机
在自动驾驶城市中用于360度感知环境的语义相机
研究背景
出行的未来是个人交通的自动化,这将带来重大的社会、经济和生态效益。自动化电动交通将缓解大规模城市化和持续交通拥堵带来的挑战,更有效地协调交通中的车辆将通过减少温室气体排放来解决气候变化问题。此外,自动驾驶意味着通过消除人为错误来提高道路安全性。共享汽车将更具吸引力,老年人或残疾人的流动性将得到改善。然而,由于关键技术缺乏成熟,特别是在复杂的城市地区,全车自动化是一个长期的愿景,也是学术界和汽车行业的持续努力。
相关工作
1. 语义分割(将图像分割成有相同意义的片段):
道路中分割出的片段:车辆、行人、骑自行车的人
评价标准:
1. 如何捕获上下文线索
2. 如何维护更精细尺度的细节,例如形状和边界
3. 更高的输出分辨率
常用方法:全卷积网络(FCN)
该方法在公共基准测试上取得了最先进的成果。
特点:来自CNN的全连接层被卷积层取代
他人的工作:
L.-C. Chen,Y. Zhu等人提出的:DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs,
L.-C. Chen, Y. Zhu等人提出的:Encoder- decoder with atrous separable convolution for semantic image segmen- tation
这两种方法通过在最后的残缺块中采用扩张卷积来扩大分类CNN的感知视野,同时提供了更高的输出分辨率。其中第一种方法具有很高的内存占用,因为它在输出分辨率上提高了8倍。
可变形金字塔网络(PSPNet)通过采用并行池操作和融合不同尺度的特征来捕获全局图像信息。
另一种流行的CNN架构:编码器-译码器
B. Shahian Jahromi, T. Tulabandhula等人的论文中提出了一种用于自由空间分割的编码器-译码器网络,该网络在自动化驾驶汽车的实时多传感器感知框架的背景下处理RGBD数据。
与针对每个任务单独训练的网络相比,多任务设置中的端到端训练可以提高准确性,并产生了一种更好地泛化的解决方案。
自动驾驶需要高性能的语义分割算法。上述方法中,编码器-译码器架构实现了准确性和延迟之间的最佳折衷。因此,本文采用了高效的ERNet网络对鱼眼图像进行语义分割,以降低计算成本、提高高质量的分割。
2. 实例分割(预测每个对象的语义掩码和实例标识符,以便我们区分属于同一类别的对象)
该方法通常使用两种方法:候选区域的分割、没有候选区域的实例的分割。
基于候选区域的分割方案在实例分割方面取得了更好的结果,而单阶段方法可以实现快速推理,并且适用于自动驾驶领域。
本文在图像分割模块使用的是RetinaMask方法,因为它具有高精度、低计算成本、更重要的是降低了推理通道的复杂性,这允许使用Nvidia的深度学习推理引擎,进一步加速并简化部署。
3. 全景分割(将密集的像素分类为事物和特征类,并为图像的每个事物像素分配一个实例标识符)
全景分割可以通过同时解决语义分割和实例分割来实现。
基里洛夫等人提供基线分析法来解决这个问题,并且提出了一种端到端的可训练网络,通过采用语义和实例logits来在网络内部直接学习的全景输出。
虽然这种方法能提供准确的结果,但它们的延迟较高,因此不适合在自动驾驶环境中使用。
本文提出了一种原始的全景分割融合方案,它使用实例类来纠正语义分类,并通过在语义掩码上传播实例标识符来改进实例掩码。
该方法执行速度快,还提供了改进和统一的语义和实例分割输出,并且很容易集成到任何图像分割网络上的后处理步骤。
测试车辆设置
UP‑Drive 项目的测试车辆5台是全电动大众 e‑Golf。为了保证 360° 3D 多模态环境感知,车辆上安装了三种不同类型的传感器:摄像头、雷达和激光雷达。传感器设置中集成了五个外部同步摄像头,以覆盖车辆的近距和远距环视:一个位于挡风玻璃后面的 60° 视野摄像头和四个鱼眼摄像头。前后鱼眼摄像头水平安装在车标附近,左右摄像头安装在两侧后视镜上并向下倾斜。该系统配备四个185°宽视野摄像头,可在车辆周围提供360°覆盖,相邻摄像头之间有一些重叠。相机的鱼眼系统提供分辨率为 1280×800、JPEG 压缩为 30 帧/秒的彩色图像。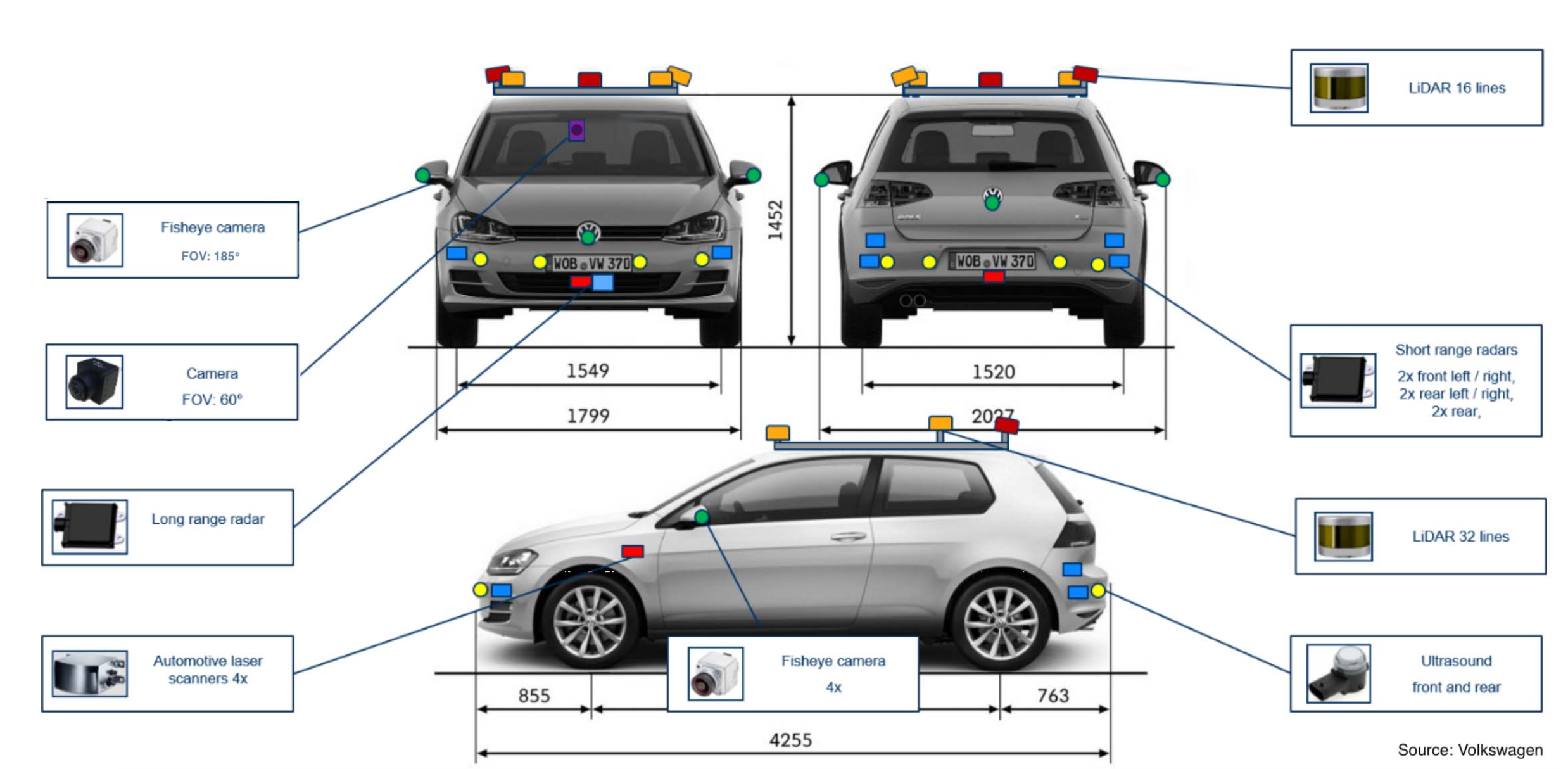
相机的鱼眼系统具有广角镜头和等效的短焦距,这决定了要捕获的大部分场景。与窄视场相机相比,图像中物体的表观尺寸更小。因此,鱼眼相机限制了分割算法的检测范围。从我们的实验中,我们获得了仅 25 米的鱼眼图像的稳健行人分割。检测远处的物体很重要,尤其是在高速行驶时。为了克服这个问题,我们在设置中引入了一个窄视场RGB摄像头,安装在挡风玻璃后面。该相机具有 60°水平视野,以30帧/秒的帧速率提供 1928 × 1208 分辨率的图像,并将检测范围扩大了三倍。完整的传感器套件如图
带有语义相机的2D感知
图像预处理:图像去畸变和展开
由于在原始鱼眼图像中,结构和物体会因为广角镜头而高度失真,因此我们需要通过图像去畸变和图像展开来获取更合适的对应场景的图像。
鱼眼图像展开过程的结果。第一行:鱼眼图像;第二行:鱼眼图像的圆柱投影。从左到右:前视图,右视图,后视图,左视图
深度语义、实例和全景分割
深度学习帮我们将分类问题扩展到表示学习,并在许多计算机视觉任务中显示出优于基于手工特征的算法的结果。
考虑到深度学习的优势和技术的先进,基于深度神经网络的解决方案很适合用于我们的自动驾驶感知软件。
- 图像分割数据集
由于缺乏公开可用的360°感知数据集,我们采用了我们自己记录和注释的内部的UP-Drive数据集来训练和评估我们提出的在鱼眼图像上进行语义和实例分割的深度神经网络。
这个数据集的一些特征:
1)捕捉了各种照明条件
记录来自德国北部的几个城市以及高速公路和乡村道路从早上到下午,考虑了不同的照明情况
2)天气多样性
时间跨度是在包括了春季夏季和秋季的几个月时间,因此在晴天、多云以及大雨等天气都有记录,甚至包括了镜头炫光、以及雨滴造成的镜头畸变
3)图像覆盖车辆前后左右的周围视野
包含了前视图像5111张、左视图像4684张、右视图像4800张、后视图像4967张
- 语义分割
通过实现一个 全卷积神经网络(FCN) 用于四个语言图像的语义分割。
介绍:
考虑到现在先进的语义架构要么非常深要么非常宽,或者以更高的的内存使用和更长的时间为代价使用复杂的层,而在车辆的自动驾驶感知系统又必须使用低功耗硬件设备来实时运行。 因此我们选择采用了一个在准确性和效率之间取得良好平衡的高效网络ERFNet
ERFNet:
该网络具有编码器‑解码器架构,其中编码器提取不同尺度的图像特征,解码器将特征组合成更高分辨率的表示。 ERFNet 的构建块是分解残差层。该层表示一维非瓶颈残差模块,它将二维内核分解为一维内核的线性组合。在这个设计中,每个 3×3 的卷积都被转换为 3×1 和 1×3 的卷积。当使用内核大小为 3 时,参数数量减少了 33%。同时,网络的内存效率更高、速度更快,同时容量增加,从而导致类似于更复杂模型的高精度分割。特征提取器通过堆叠具有扩张卷积的剩余 1D 非瓶颈块以三个尺度对特征进行编码:原始输入分辨率的 1/2、1/4、1/8。为了保留详细信息和小对象,高输出分辨率很重要。卷积层中的膨胀已被证明是一种捕获多尺度上下文的有效机制,这对于正确分类至关重要。轻量级解码器由一维非瓶颈块组成,并从编码器的最后一层恢复空间和语义信息
实现:
我们在具有四个Tesla V100 GPU的系统上用Pytorch框架实现我们的模型。该网络经过150个epoch的训练,每个GPU的批量大小为12个图像,多项式学习率从0.0025开始衰减。另外,交叉熵损失函数用过Adam优化器来优化。我们将图像裁剪为1280*640,并应用随机水平翻转和随机左右平移。这个网络使用Cityscapes数据集上的预训练权重进行初始化。
- 实例分割
我们的深度实例分割网络既要准确高效又要允许使用TenseorRT等深度学习推理引擎进行优化和部署。
为了保持整个感知系统的处理时间较低,又车辆前部的区域包含了最重要的关于安全航行所需的环境信息,所以我们只对前鱼眼图像和窄视场图像进行实例分割
我们用于实例分割的最终解决方案采用 RetinaMask
它使用 Mask R‑CNN 类型的实例掩码预测头扩展了最先进的单次目标检测器 RetinaNet 。对于特征提取主干,我们使用带有 5 级特征金字塔网络 (FPN) 的 ResNet‑50 。 FPN 通过编码从 1/4 到 1/64 的多分辨率表示来实现多尺度对象检测。 FPN 遵循原始实现 ,具有 256 个特征图和 5 个锚定尺度。具有四个卷积层的边界框回归和分类头附加到金字塔的每个级别。边界框预测被聚合、过滤并分发到 FPN 中的层。接下来,ROIAlign 操作从每个预测的边界框中采样相同数量的特征(14 × 14),最终由具有四个卷积层和一个转置卷积的掩码预测头处理。最后,[1 × 1] 卷积生成大小为 28 × 28 的最终类别掩码。
我们在来自 UP‑Drive 数据集的鱼眼和窄视野图像上训练两个实例分割网络。该网络在 Microsoft COCO 数据集和 Cityscapes 数据集上进行了预训练。我们将批量大小设置为 16 个图像,并以 0.01 的基本学习率训练 30k次迭代,在 20k 次迭代时减少 10 。损失函数的优化是使用随机梯度下降 (SGD) 完成的。鱼眼图像被裁剪为 1280 × 640,然后在训练期间使用图像的较短边缘进行缩放
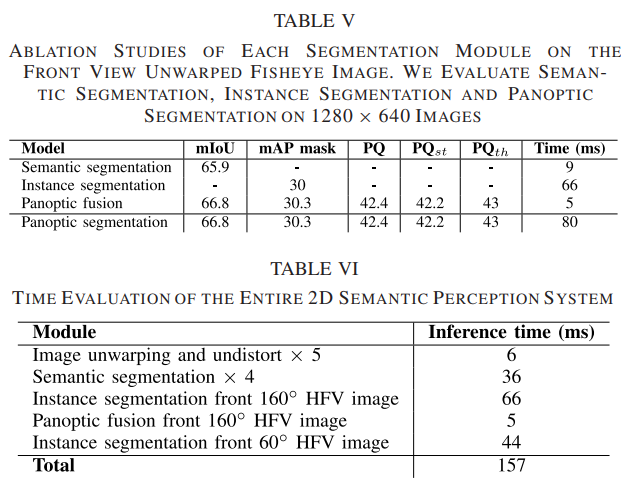
- 全景分割
在全景分割之前,我们发现:
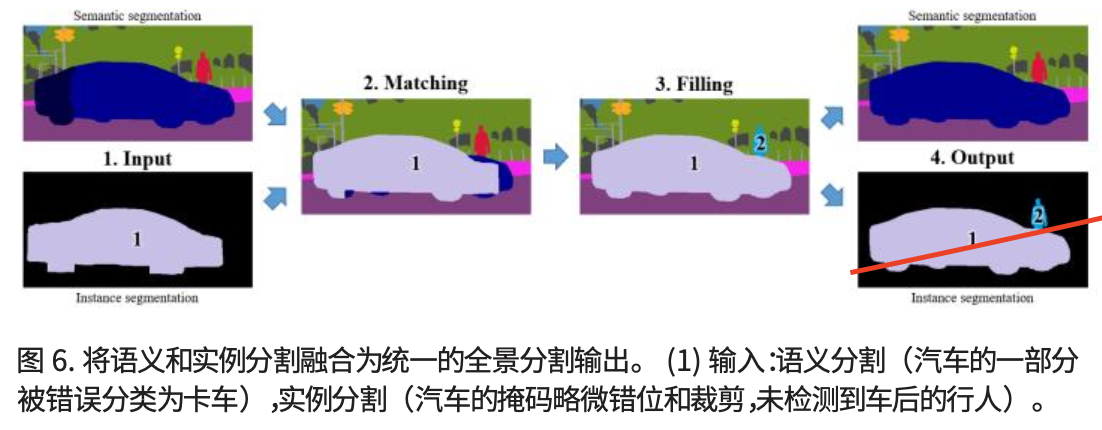
实例分割掩码由于其低分辨率(28*28)而更加原始,并且可以观察到对象边界处的错误,尤其是在对象比较大的情况下,而语义分割提供了事物之间的良好分割和填充像素,但是会混淆同一类别的一些东西。
因此我们考虑通过融合语义分割和实例分割输出来作为全景分割的方案,这有效解决了语义类之间的实例级重叠和冲突。
融合过程如图所示:
- 网络集成和部署
最终,我们将分割网络、两个实例分割网络(一个用于鱼眼和一个用于窄 HFV 图像)和全景分割融合算法,如图所示集成到我们在ADTF 中运行的感知软件中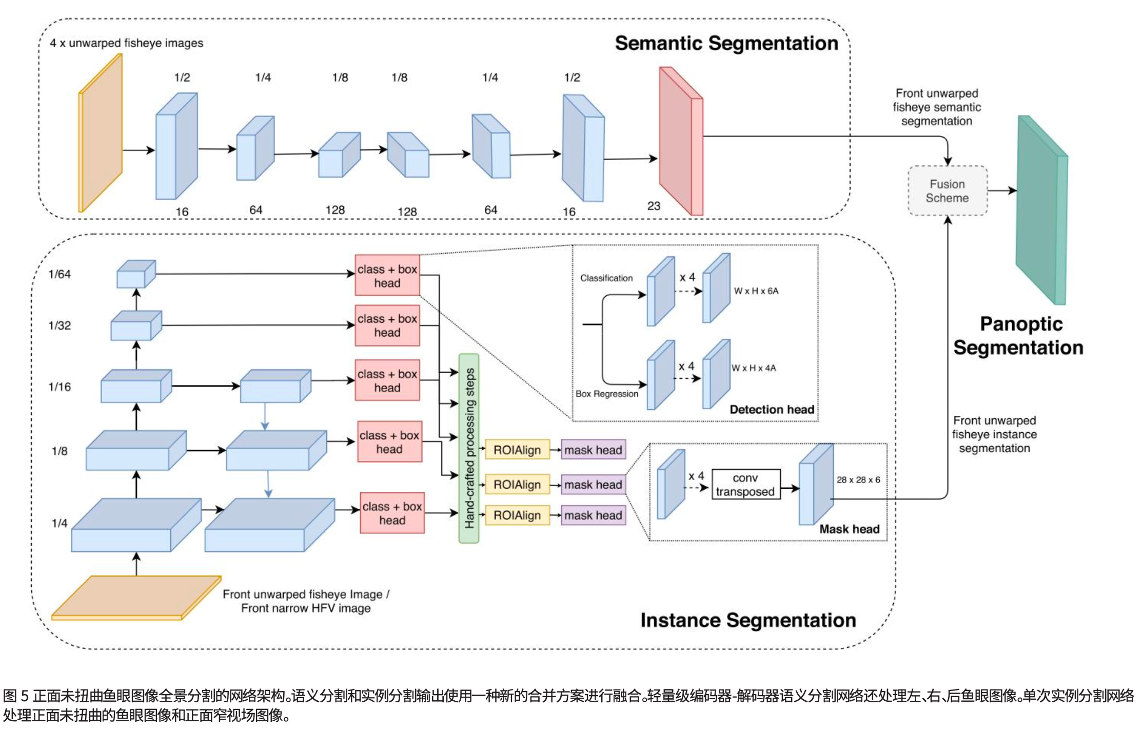
实验
在本论文中,我们提供了 UP‑Drive 数据集上的 2D 语义、实例和全景分割的实验结果。
实验指标:
1. 评估指标:我们使⽤标准mIoU(平均交集⽐联合)指标评估语义分割。
2. 执行时间:在批量大小为 1 的 NVIDIA GTX 1080 GPU 上测量。
评估⻥眼图像的语义分割⽹络,对应于前、左、后、右视图: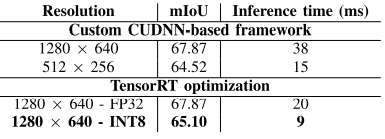
图像分割结果:
⻋辆的前部区域被两个摄像头覆盖:
⼀个窄的 60°⽔平视野摄像头,可在增加深度时提供实例分割;
⼀个较宽的 160°⽔平视野摄像头,可提供实例,近程的语义和全景分割。

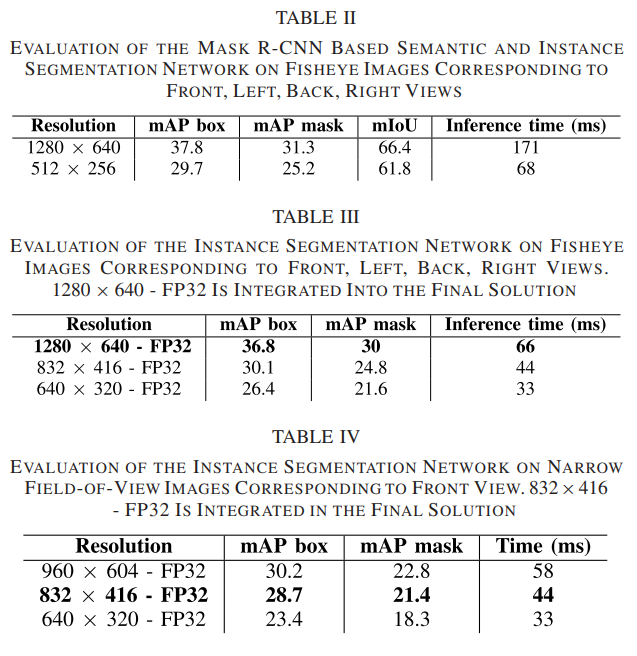
与其他⽅法相⽐,我们的解决⽅案最快,为 68 ms,并且与使⽤更⾼分辨率图像的⽹络实现了可⽐的语义分割 mIoU。然⽽,我们观察到我们的实例分割结果不太准确,因为在下采样图像中检测和分割⼩物体更加困难。从实际的⻆度来看,考虑到施加的约束,我们在速度和准确性之间取得了良好的平衡,以低得多的计算成本获得了具有竞争力的结果。
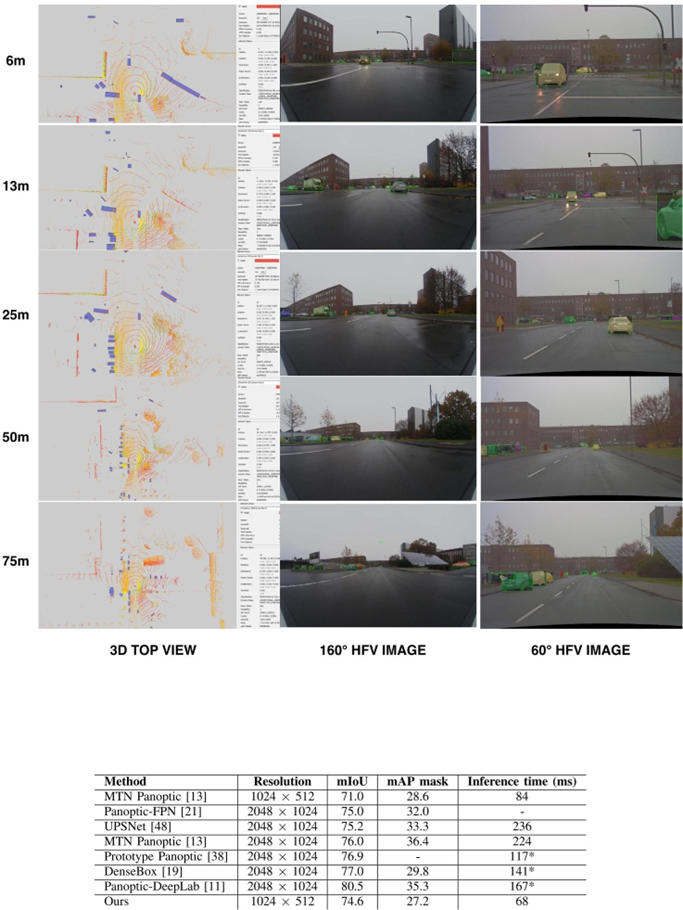
宽视场和窄视场实例分割的比较。行人在 3D 顶视图图像中标有绿色框,并且宽视场和窄视野图像中的红色边界框。在第一列中,我们提供检测到的3D点云的鸟瞰图对象。最佳彩色和变焦效果。
总结
从多个角度构建全自动车辆原型十分具有挑战性,其中包括:选择最合适的传感器套件、开发在现实世界场景中提供准确结果的快速且稳健的算法、创建用于训练深 度学习算法的质量和完整数据集,以及算法的集成和车辆上的部署。
我们的语义摄像机设置可感知车辆周围的 360°。我们的第一个解决方案仅使用安装在所有四个方向上的鱼眼相机。然而,分割和检测范围仅限于车辆周围的近距离。在行人的情况下,分割在 25 米范围内是稳健的,仅适用于非常低速的驾驶和停车操作。对于左视图、右视图和后视图,即使在高速行驶 的情况下,近距离检测也为机动预测和决策提供了足够的信息。然而,远距离 的检测和分割是必要的,尤其是在前视图上。在我们的最终解决方案中,我们 得出结论,鱼眼摄像头和用于前视的窄视场摄像头对于覆盖近距和远距范围都是必要的。此外,另一个重要方面是可以通过处理更高分辨率的图像来增加检测范围。
在 UP‑Drive 项目中,我们成功开发了一种能够在城市区域安全导航的自动驾驶汽车。我们为基于鱼眼和窄视场语义相机的环境感知提供了一个模块 化的基于深度学习的解决方案,具有语义、实例和全景分割功能。在本文中,我 们介绍了我们在开发语义环境感知系统时遇到的挑战,因为对准确性、鲁棒性和实时性能的要求很高。我们研究了多种解决方案,激发了我们最终的设计选择,展示了有关分割模块与软件集成的详细信息,最后我们讨论了项目4年过程中的经验教训。





