
Bilibili用户社交网络分析
Bilibili用户社交网络分析
数据集的获取
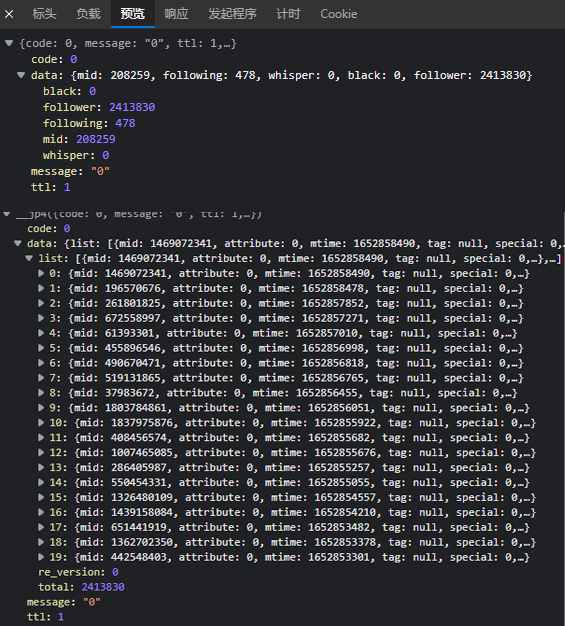
本次实践的数据集是通过爬取bilibili网页端的数据获得,其数据在网页端的存储格式如图 1 所示。本节下面会详细介绍如何实现数据的爬取。
数据库设计
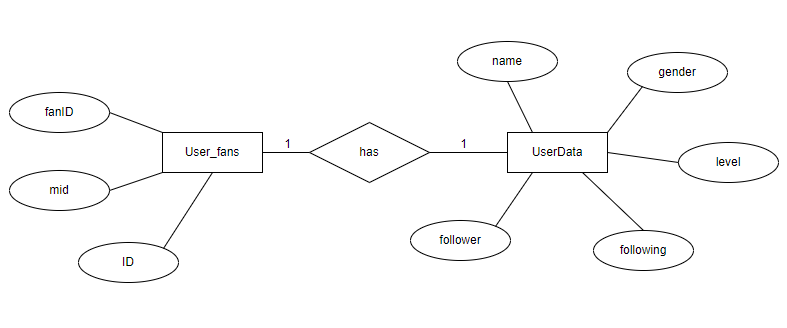
在了解数据的具体结构后,本人据此设计了数据库的存储格式。该数据库的ER图如图 2 所示。User_fans表中主要包括三个字段,主键ID,和两个外键mid,fanID。其中mid代表当前用户的ID,fanID代表该用户粉丝的ID。UserData表主要用来存储用户的详情信息,包括姓名、性别、等级、关注者数量以及粉丝数量。User_fans与UserData之间存在着关联关系,也就是说每一个用户都有他的详情信息。
爬虫的编写
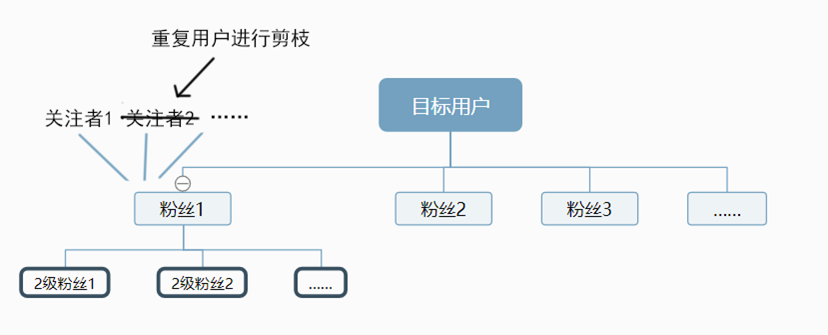
本文的爬虫功能是基于 python 3.9 实现的,调用了外部库 requests 来获取网络请求,以及 json 库来解析 json 数据。爬取数据的逻辑是一个双向层次遍历,其结构如图 3 所示。由于事先我们无法获得所有用户的ID,所以只能以一个用户作为切入点,遍历其粉丝列表和关注列表,并以此为基础,获取更多用户的信息。
获取数据后的初步分析
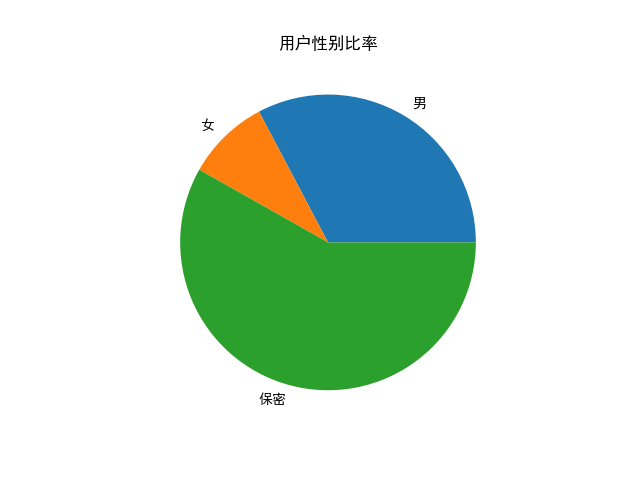
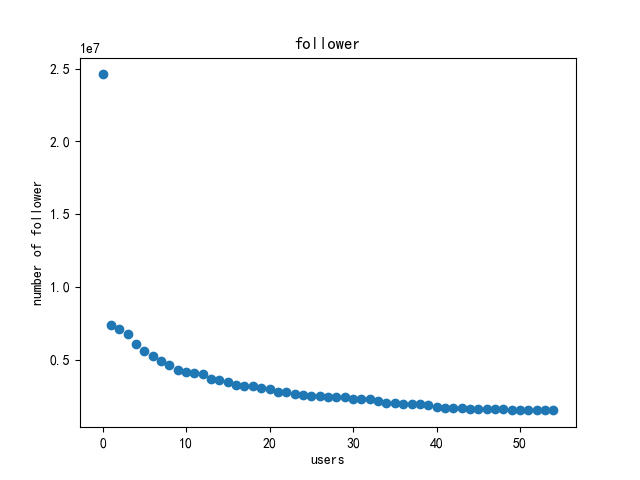
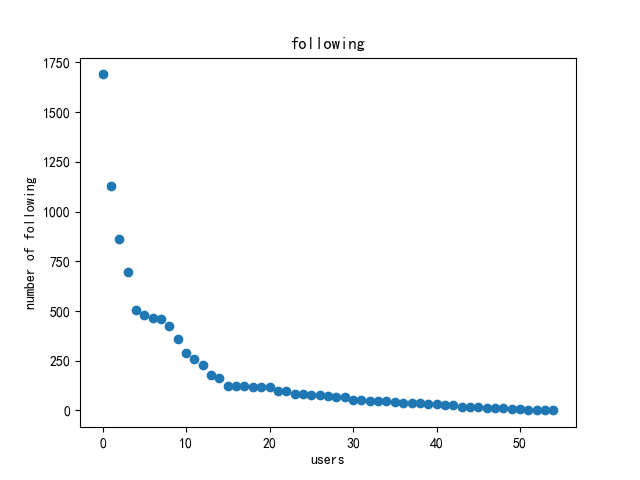
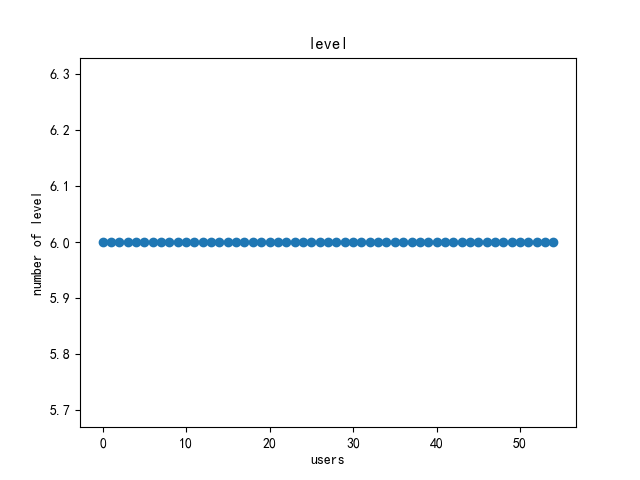
本次实验中共爬取了 8801 条数据,在做网络分析前作者对其进行了初步的分析,包括性别分布、粉丝数量统计、关注者数量统计以及用户等级统计等。分析可得,性别保密的用户占大多数,其次是男性、女性;用户等级都是最高等级6级;从整体上来看每个用户关注者数量和粉丝数量都较高,但标准差较大。详细结果如图 4-7 所示。
网络结构分析
网络可视化
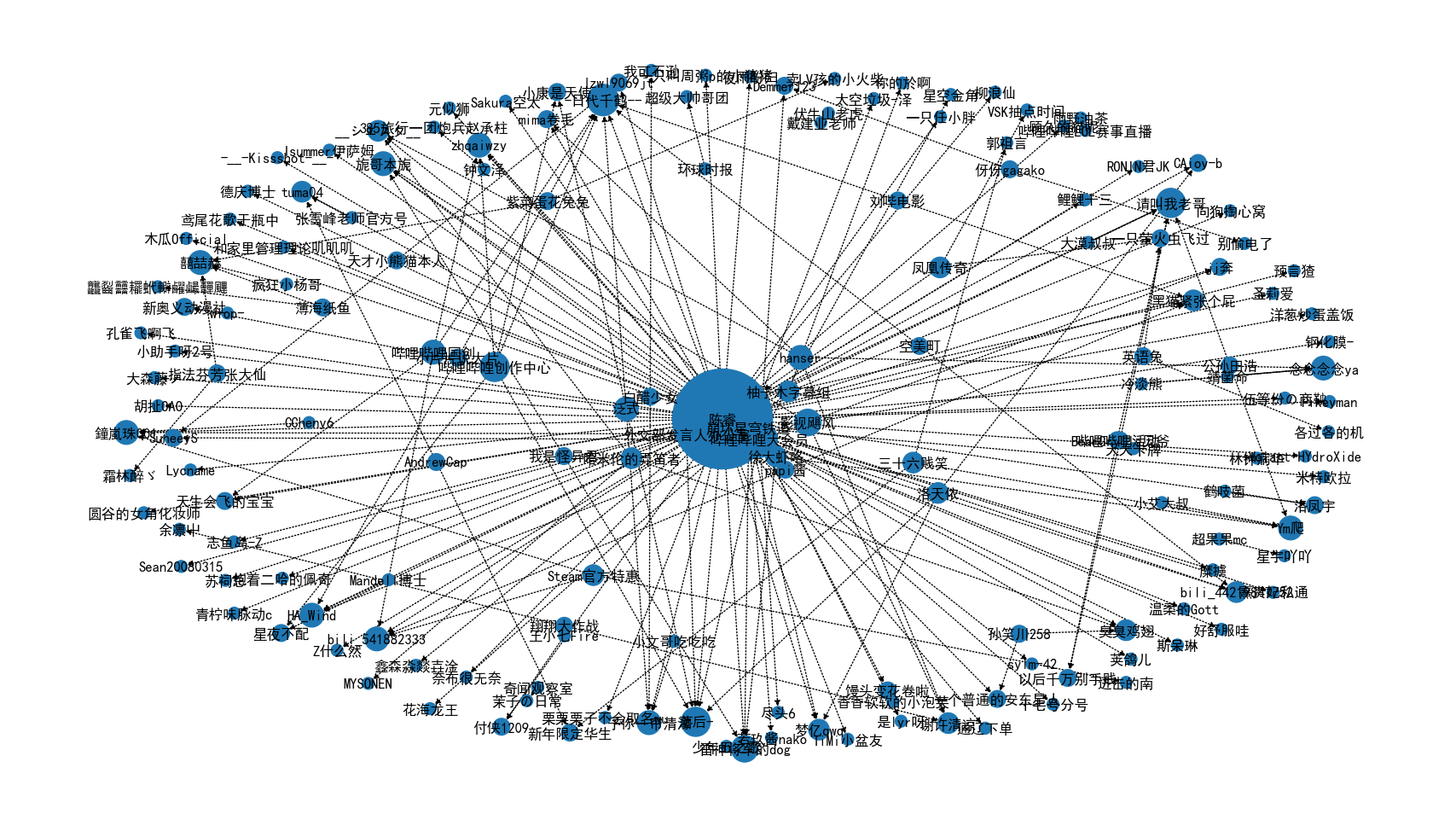
网络可视化主要基于包 networkx [1] 和 matplotlib 实现。这里使用了有向图来表达关注与被关注关系,每个节点的出度代表被关注关系,入度代表关注关系。为了方便观看,作者将粉丝数量大于150万的核心用户提取出来进行分析,并将用户的ID转化为用户名,最后根据每个节点的度数对节点的大小进行了缩放处理。最终结果如图 8-9 所示。

网络度分布与聚类系数
度分布是指网络中度为k的节点的出现概率,而聚类系数表示一个图中节点聚集程度的系数。本文通过 networkx 包中自带的 degree_histogram 方法和 degree_centrality 方法对这两个指标进行统计。其代码如下所示。
1 | # 网络度分布 |
代码运行的结果如图 10-11 所示。
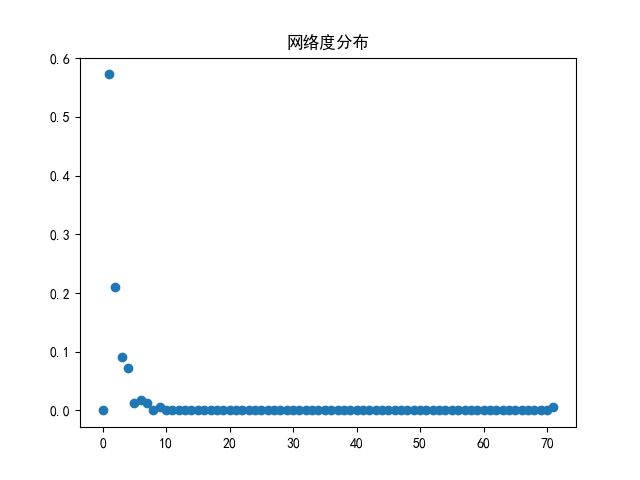
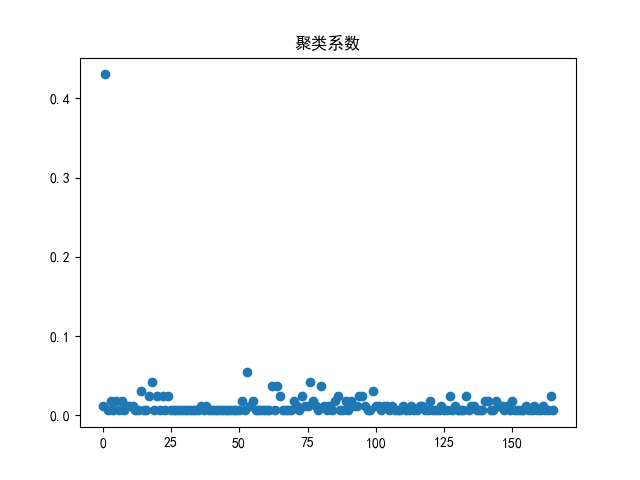
从统计结果中可以看出网络的度主要分布在 1-6 附近,但其中的一个节点的度数达到了70以上。从整体上来看满足星型网络的分布情况,即网络通过中心节点将许多点连接而组成。从聚类系数上来看也是,一个节点的聚类系数远远高于其他所有节点,这也验证了前面所述的观点。
网络其他指标
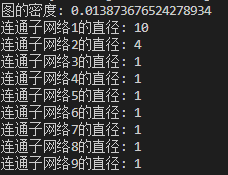
网络的密度
网络密度是网络中实际存在的边数与可容纳的边数上限的比值。本文通过 networkx 中的 density 方法实现。其代码如下所示。
1 | # 网络的密度 |
网络直径
网络直径是指网络中任意两节点间距离的最大值。由于本实验中生成的是有向图,可能存在非连通网络,因此作者现将网络分割成数个连通子网络,然后再进行统计。其代码如下所示。
1 | # 网络直径 |
上述代码的运行结果如图 12 所示。
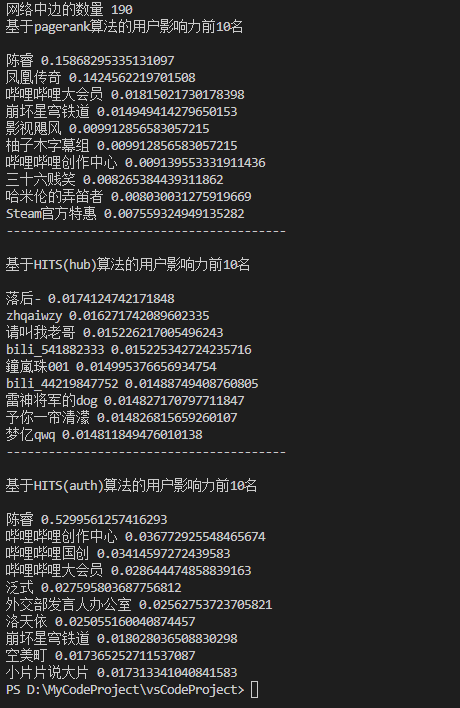
用户影响力发掘
在对本实验中的实证网络进行一系列分析后,作者还对本次爬取到的用户的影响力进行了分析,分别计算出了用户权威性最高的前十位用户,以及用户枢纽性最高的前十位用户。这里作者采用了两种方法进行计算,分别是 PageRank 和 HITS 方法 [2]。其主要代码如下所示,运行结果如图 13 所示。
1 | # PageRank |
结语
本文爬取了Bilibili网页端的用户信息,并对该实证网络进行了一系列分析,主要讨论了用户信息分布、网络的结构以及用户的影响力信息。从分析结果可看出该网站用户群体中有一位处于主导地位。由于设备受限,本文只爬取了接近9000条数据,并只筛选出粉丝数大于150万的核心用户进行分析,结果可能与真实分布情况存在一些偏差。不过,该结果也能反映出一些有意义的信息。希望读者通过观看本文,能对Bilibili的用户分布情况有进一步的了解。
参考文献:
[1] 司六米希.【复杂网络】实证网络可视化及其分析 - 含度分布,聚类系数,网络直径,度关联性,权重分析 (性质解析及代码)【python+networkx】[CP].CSDN, [2022-05-20]. https://blog.csdn.net/weixin_50927106/article/details/123921734
[2] nana-li.PageRank算法和HITS算法 [CP].CSDN, [2018-07-27]. https://blog.csdn.net/quiet_girl/article/details/81227904




